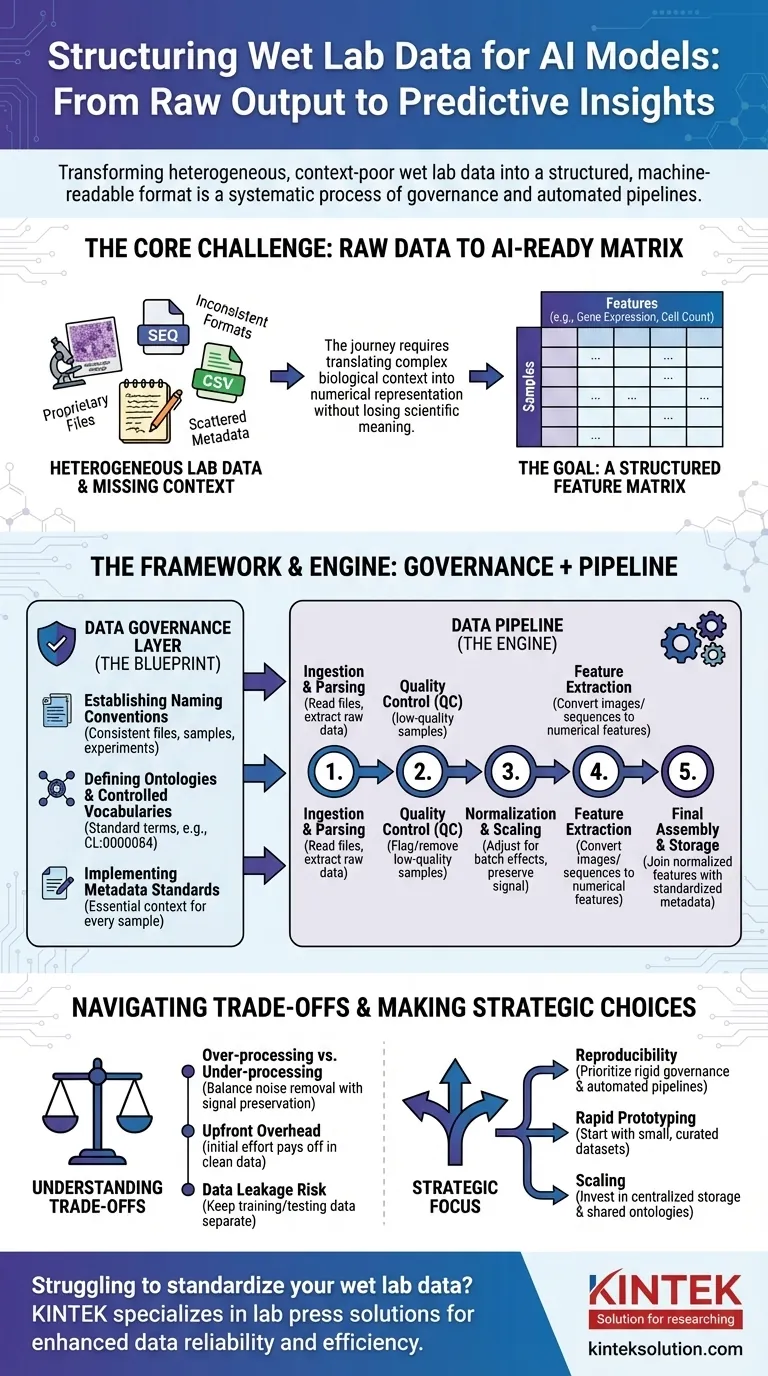
Чтобы подготовить данные мокрой лаборатории для ИИ, вы должны преобразовать их из необработанного, часто непоследовательного состояния в структурированный, машиночитаемый формат. Это не единичный шаг, а систематический процесс, включающий управление данными для создания четких правил, за которым следуют конвейеры данных, автоматизирующие очистку, нормализацию и структурирование необработанных экспериментальных результатов в согласованный формат, подходящий для обучения модели.
Основная задача заключается не просто в переформатировании файлов. Речь идет о систематическом преобразовании сложного биологического контекста — такого как экспериментальные условия, история образца и методы измерения — в структурированное, числовое представление, из которого модель ИИ может извлекать уроки, не теряя при этом критического научного значения.

Основная проблема: от необработанных данных к данным, готовым для ИИ
Путь от лабораторного стола к прогностической модели полон проблем с данными. Необработанные выходные данные научных приборов редко, если вообще когда-либо, готовы для непосредственного использования в алгоритме ИИ.
Гетерогенность лабораторных данных
Данные мокрой лаборатории поступают в самых разных форматах. Сюда входит все: от проприетарных файлов секвенаторов и микроскопов до простых CSV-файлов с планшетных ридеров, каждый со своей структурой и особенностями.
Однако модели ИИ требуется унифицированный формат.
Проклятие отсутствующего контекста
Критическая информация, или метаданные, часто разрознена. Она может находиться в лабораторном журнале ученого, в отдельной электронной таблице или просто в его голове. Без этого контекста (например, какой препарат был применен, температура, используемая клеточная линия) числовые данные бессмысленны.
Цель: матрица признаков
В конечном итоге большинству моделей ИИ требуются данные в виде матрицы признаков. Это простая таблица, где строки представляют отдельные образцы (например, пациента, лунку клеточной культуры), а столбцы представляют признаки (например, уровни экспрессии генов, измерения морфологии клеток, концентрации белков).
Основа для стандартизации: уровень управления данными
Прежде чем вы сможете создавать автоматизированные конвейеры, вы должны установить правила. Это управление данными — план, который обеспечивает согласованность во всех экспериментах и командах. Это самый критический и часто упускаемый из виду шаг.
Установление правил именования
Простое, но мощное правило — это применение последовательной схемы именования файлов, образцов и экспериментов. Это позволяет программно связывать и отслеживать данные от их происхождения до окончательного анализа.
Определение онтологий и контролируемых словарей
Онтология предоставляет стандартный набор терминов для описания биологических сущностей. Например, вместо того, чтобы разрешать «T-cell», «T lymphocyte» и «Tcell», контролируемый словарь навязывает один термин, например CL:0000084 из Онтологии клеток.
Это предотвращает двусмысленность и гарантирует, что данные из разных экспериментов действительно сопоставимы.
Внедрение стандартов метаданных
Вы должны определить минимальные метаданные, которые должны быть зафиксированы для каждого образца. Часто это включает источник образца, экспериментальные условия, настройки прибора и дату. Это правило гарантирует, что ни одна точка данных не станет осиротевшей, оторванной от своего контекста.
Двигатель трансформации: создание конвейера данных
При наличии правил управления вы можете создать конвейер данных. Это серия автоматизированных программных шагов, которые преобразуют необработанные данные в конечную матрицу признаков, готовую для ИИ.
Шаг 1: Сбор и парсинг данных
Первая задача конвейера — найти и прочитать необработанные файлы данных. Этот шаг включает написание специальных парсеров для формата вывода каждого прибора для извлечения основных измерений и любых связанных метаданных.
Шаг 2: Контроль качества (QC)
Не все данные являются хорошими данными. Конвейер должен автоматически помечать или удалять некачественные образцы на основе предопределенных метрик, таких как низкое количество клеток в эксперименте по визуализации или плохое качество считывания с секвенатора.
Шаг 3: Нормализация и масштабирование
Измерения из разных партий или планшетов часто имеют технические вариации. Нормализация — это важнейший шаг, который корректирует данные, чтобы сделать измерения сопоставимыми между экспериментами, удаляя технический шум, сохраняя при этом биологический сигнал.
Шаг 4: Извлечение признаков
Необработанные данные часто не представлены в формате признаков. Изображение, например, должно быть обработано для извлечения числовых признаков, таких как размер, форма и интенсивность клетки. Последовательность ДНК может быть преобразована в вектор частот k-меров. Этот шаг превращает сложные данные в числа, которые может использовать ИИ.
Шаг 5: Окончательная сборка и хранение
Наконец, конвейер объединяет нормализованные признаки со стандартизированными метаданными. Это создает окончательную, чистую матрицу признаков, которая затем сохраняется в стабильном, запрашиваемом формате (например, Parquet или базе данных) для обучения модели.
Понимание компромиссов
Структурирование данных не является нейтральным процессом. Каждый сделанный вами выбор может повлиять на производительность и интерпретацию конечной модели.
Чрезмерная обработка против недостаточной обработки
Агрессивная нормализация или фильтрация иногда может удалять тонкие, но важные биологические сигналы. И наоборот, неспособность удалить технический шум гарантирует, что ваша модель будет учиться на экспериментальных артефактах вместо биологии. Это постоянный баланс.
Стандартизация создает первоначальные накладные расходы
Внедрение управления данными требует значительных первоначальных усилий и одобрения всей команды. Сначала это может показаться замедлением исследований, но оно приносит огромные дивиденды, предотвращая месяцы работы по очистке данных позже.
Опасность утечки данных
Критически важная функция конвейера — разделение данных для обучения и тестирования. Если информация из тестового набора (например, его общее распределение) используется для нормализации обучающего набора, производительность вашей модели будет искусственно завышена, и она потерпит неудачу в реальном мире.
Правильный выбор для вашей цели
Ваш подход к структурированию данных должен определяться вашей конечной целью.
- Если ваша основная цель — воспроизводимость: Отдавайте приоритет жесткому управлению данными и полностью автоматизированным конвейерам с контролем версий с первого дня.
- Если ваша основная цель — быстрое прототипирование: Начните с небольшого, вручную отобранного набора данных для проверки вашего подхода к ИИ, прежде чем инвестировать в полномасштабный конвейер.
- Если ваша основная цель — масштабирование в крупной организации: Инвестируйте значительные средства в централизованное хранение данных, общие онтологии и общие компоненты конвейера, чтобы предотвратить создание информационных "бутылочных горлышек".
В конечном итоге, отношение к вашим данным с такой же строгостью, как и к вашим экспериментам в мокрой лаборатории, является основой для создания успешного и надежного биологического ИИ.
Сводная таблица:
| Шаг | Ключевое действие | Цель |
|---|---|---|
| Управление данными | Установление правил именования, онтологий, стандартов метаданных | Обеспечение согласованности и сопоставимости между экспериментами |
| Конвейер данных | Сбор, парсинг, КК, нормализация, извлечение признаков, сборка | Автоматизация преобразования необработанных данных в готовую для ИИ матрицу признаков |
| Компромиссы | Баланс между чрезмерной и недостаточной обработкой, управление накладными расходами | Оптимизация производительности модели и предотвращение утечки данных |
Испытываете трудности со стандартизацией данных вашей мокрой лаборатории для ИИ? KINTEK специализируется на лабораторных прессах, включая автоматические лабораторные прессы, изостатические прессы и нагреваемые лабораторные прессы, обслуживая лаборатории для повышения надежности данных и эффективности экспериментов. Позвольте нам помочь вам достичь стабильных результатов — свяжитесь с нами сегодня, чтобы обсудить ваши потребности и узнать, как наши решения могут поддержать ваши исследования, основанные на ИИ!
Визуальное руководство